Get insights into the type of problems I tackle by exploring a selection
of my own data science experiences. Each project relies heavily on the
indicated technique.
You will notice that many topics leverage more than one modeling strategy,
and that's fine. In practice you have to understand the problem and choose
your toolset accordingly. Models are just tools you use to help solve the
problem. As such you need to be familiar and comfortable with a variety
of methodologies.
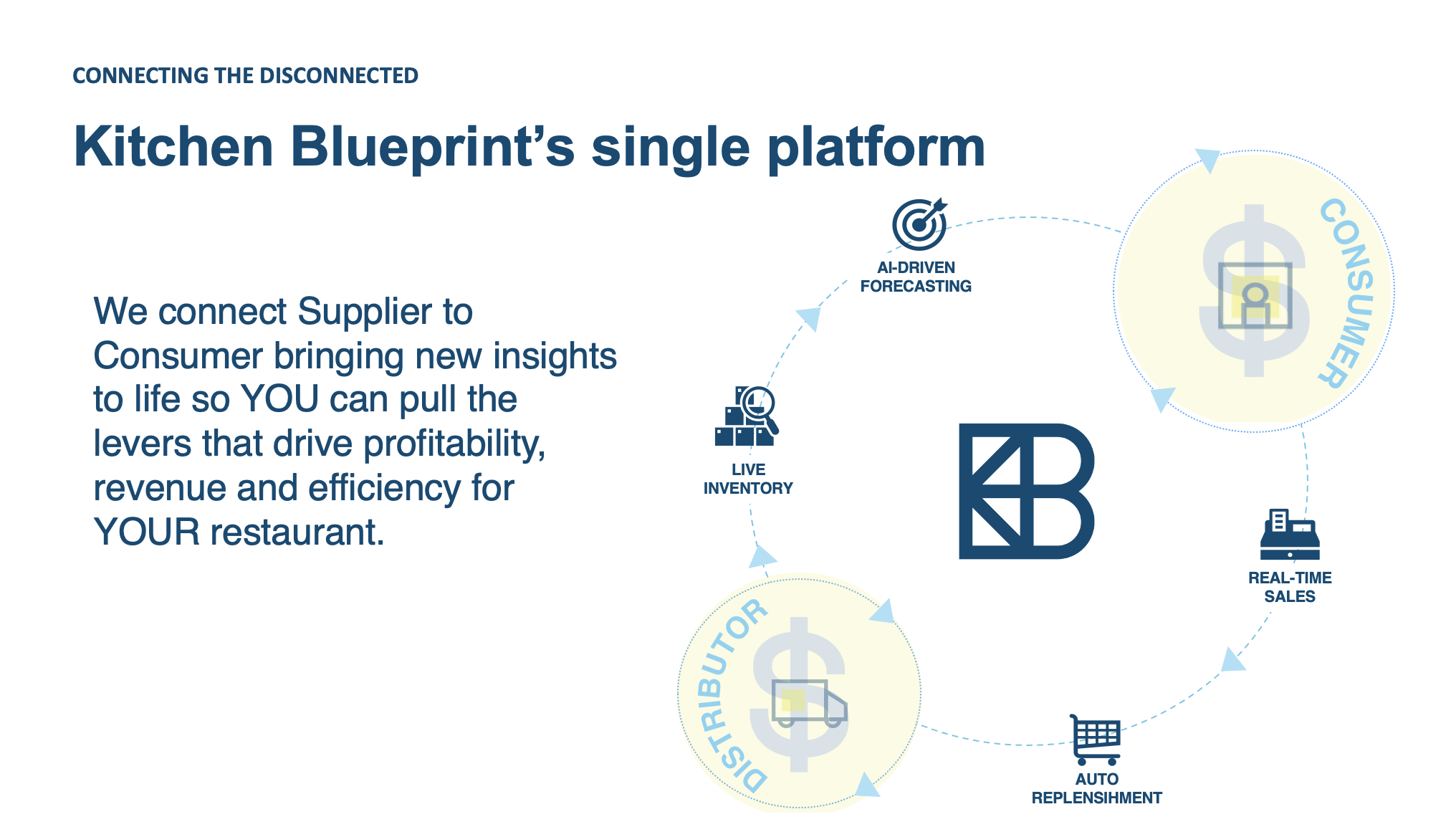
At Cargill I led the design and deployment of Kitchen Blueprint,
an innovative application within the proprietary packaged
food division, focusing on serving restaurant partners.
Kitchen Blueprint utilizes a sophisticated forecasting algorithm
to predict ingredient consumption into the near future for
individual restaurants. Leveraging these forecasts, and real-time
inventory information, the application recommends optimal
ingredient ordering quantities, effectively reducing food waste
by approximately 30%.
Scalability posed a significant challenge for this project, as we
were required to run hundreds of individual ingredient-level
forecasts per location. To address this, I developed a fully automatic
custom time-series module I named FIFE (Finite Interval Forecasting).
This surpasses standard AutoML functionality by similarly enabling
auto-selection of models and hyperparameters, but also including
robust edge-case handling and greater intelligence in model selection.
This advanced forecasting process runs on the Azure cloud platform.
As I lead the expansion of Kitchen Blueprint to accommodate new
edge-cases and business needs, due to FIFE the solution remains
adaptable. Kitchen Blueprint continues to demonstrate its
effectiveness in mitigating food waste, enhancing profitability,
and promoting sustainability across our restaurant partners.
Recommendation Engine
Personalized Playlist Generation
At iHeartRadio, I led the back-end execution of the flagship
product, 'My Playlist,' which is a core feature on the app.
The algorithm I designed and deployed generates personalized
music playlists based on a small handful of user-selected songs.
It recommends additional songs to the user to help them further
enhance their custom playlist, and if too few songs were selected
to fill out the playlist entirely it will automatically populate
these on the user's behalf.
Named the 'Most Popular New Feature of 2021', the product has been
a resounding success, significantly increasing both revenue and user
engagement. Analysis shows that users spend significantly more time
listening to their own personalized playlists than for similar
pre-curated content on the app.
So, how does this work? Well, the recommendation system employs a
combination of Matrix Factorization, Bayesian Inference, and
statistical measures to find similar tracks to those manually
entered into the playlist. However, this goes beyond simple similarity
matching and incorporates factors like song enjoyment, estimated
revenue based on user listening time, and track royalties paid by
iHeartRadio.
But just because a song is similar does not mean that the
listener will enjoy it. To ensure track quality, I designed a
custom star-ranking system, relying heavily on Bayesian re-ranking,
to judge the 'enjoyability' of tracks. The details of this system
are outlined in the iHeartRadio Tech Blog I link to at the end
of this section.
Finally, we come to ordering of tracks within the playlist.
Optimizing the track order posed challenges due to balancing user
engagement with royalty considerations. I devised a graph-based
reinforcement learning algorithm to optimize the ordering of
the tracks, ensuring an enjoyable listening experience while
adhering to licensing rules and reducing costs.
For a comprehensive exploration over the technical aspects of
the star-ranking system discussed above please refer to my
iHeartRadio Tech Blog
(Link Here).
Reinforcement Learning
Dynamic Sales Plan Creation
This project provides a solution to a pressing challenge faced
by the protein arm at Cargill. They required detailed insights
the future of the ever-evolving boxed-beef market. You see, sales
contracts can be signed months before shipment, but the USDA only
provides signed contract prices for the first 3 weeks into the
future. Hence, for the medium term (4-8 weeks out) the business
is essentially blind.
The business already had an implemented solution, but it was
known by them to be intractable, requiring days to run, and even
then only providing a fraction of the insights they required.
I considered whether this problem was best solved as an optimization
problem, but ultimately, decided to reimagine the project using a
probabilistic approach.
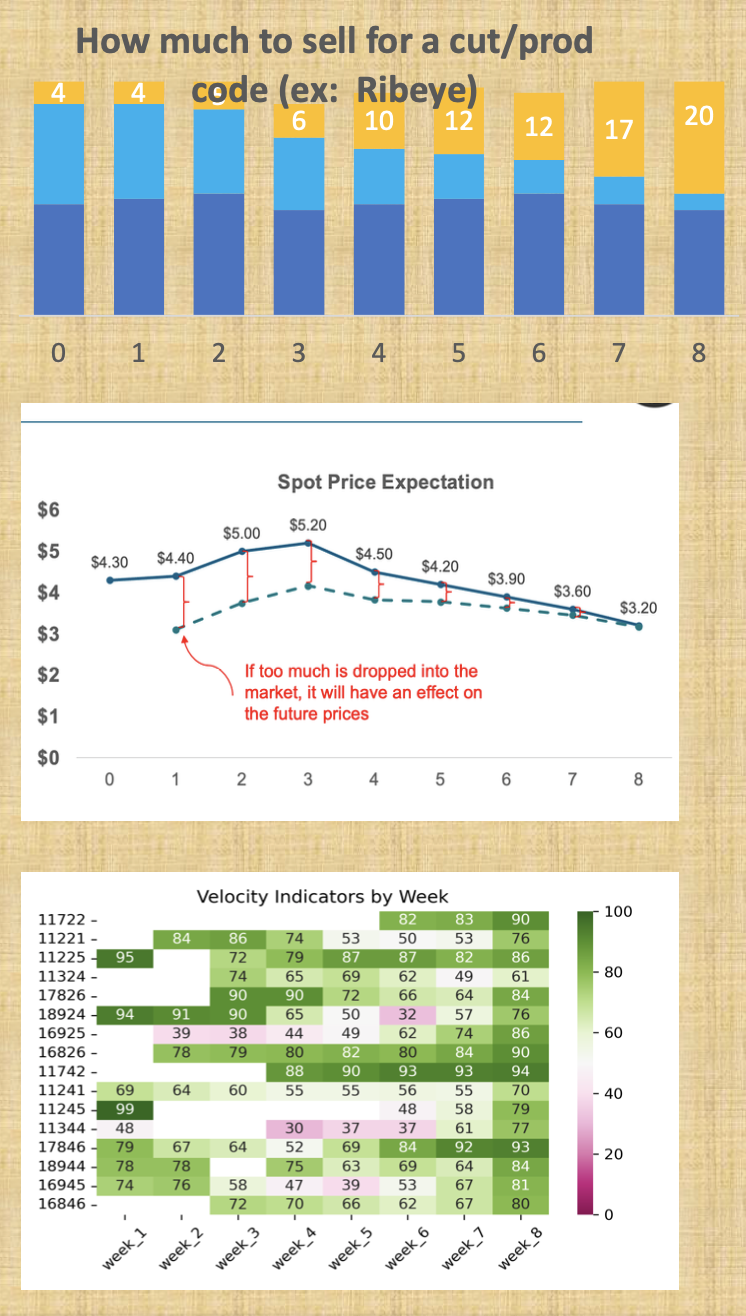
This solution combines forecasting future prices based on expected
market conditions, simulating hundreds of possible future
perturbations, and reinforcement earning to generate a recommended
sales "velocity" for the upcoming 8 weeks. These insights are then
used to guide sales managers on how much of their existing stock
they should target to move each week, where higher "velocities"
indicate weeks where they should be more willing to sell.
This is a multi-step process. The first portion forecasts the
expected prices assuming nothing critical occurs in the market.
The second calculates the price elasticity based certain factors.
The third takes all inputs and simulates thousands of possible
scenarios, ultimately providing the sales plan belonging to
the statistically most profitable outcome. In practice this
works quite well and has been estimated by the protein arm to
increase profits by around one million dollars.
Regression
AI Pricing and Promotion Decomposition
The meat-based protein arm of Cargill had a problem. When they
made decisions to change product prices, or run product promotions,
they were no longer seeing the same success they used to. In
fact, they were starting to see market-share fall. What they
needed was a data-driven product.
I developed a sophisticated solution to inform the business
of the optimal grocery store pricing strategy as well as the
expected impact for different types of promotions the stores
could run. By using this the business can simulate the expected
impact of any decision they make, or decisions made by key
competitors.
To do this I created an advanced regression model, based on
econometric principles, which forecasts the volume sold for
that each week based on a myriad of factors. The "secret sauce"
is that most of these factors represent an important lever
or dial the business or their competitor's control.
The simulation aspect of this solution leverages the extracted
elasticity for our own price changes, the elasticity for
competitors price changes on the sale of our products, the
boost in sales we receive from a particular type of promotion,
and many others.
Deployment of this solution, and incorporating it into the
toolset used by the sales team, drove a significant increase
in profits and I am currently overseeing the scaling of this
into additional stores. I designed this to be a platform,
and not a set of standalone solutions. This conscious
architectural design choice means that only relatively small
alterations are needed for moving it into new locations.
Classification
Financial Product Forecasting Solution
Cargill purchases produce from farmers in a multitude of ways.
For example, farmers can show up unannounced and sell their
crop on-the-spot at whatever the current market-price is,
they can negotiate a static price months ahead of time, or
choose other complex options. During these negotiations farmers
also provide an estimate for the amount to be delivered, but based
on many factors this is also subject to change. In a situation
like this, the more insight Cargill has at their disposal the better
they can negotiate and plan targeted marketing strategies.
After discussing the details at length with business stakeholders
and sales managers I devised a sophisticated solution which
reliably provides the required forecasts. These include the ikelihood
that a farmer will arrive within a particular period, the amount
of crop they are likely to bring if they arrive, and the financial
product the farmer is most likely to select during contract negotiations.
My solution enabled a successful targeted marketing campaign, leading to
a notable 12% increase in closure rate.
For the insights such as likelihood to arrive and amount of crop
to bring I ultimately found that a statistical modeling approach,
as opposed to ML, was most effective. For the question of the
financial product they prefer I built a hierarchical classification
model. This first forecasts the most likely family of product they
prefer, and then once identified further refines the recommendation
by forecasting the most likely product within this family.
Generative AI
LLM Assisted Code Migration
Translating legacy code into newer systems, with updated syntax
or even a newer language, is a growing problem across most large
companies. Cargill is no exception. Migrating extremely important
systems written in archaic languages is difficult, time-consuming,
and extremely expensive. This project seeks to minimize this burden
by Leveraging state-of-the-art LLM modeling strategies.
One of the first things I investigated was whether we can
translate the code directly into the new language and system,
leaving the developer to briefly assess the new code via visual
inspection, run pre-existing robust unit tests, and address any
minor differences found. However, I quickly found that the
problem wouldn't capitulate this easily. In many cases the
integrations with the new system were different enough that
the LLM was not able to sufficiently understand the differences
and the developer was finding no significant benefits as they
had to check through every line regardless.
With this in mind I changed tactics and although I did still
provide this "possible" code translation, I added additional
insight to help the developer identify the portions of the
code most likely to need careful examination. To do this I
supplied a customized pseudocode which summarizes the original
code in a human-readable format, while explicitly indicating
the sections where it believes that integration changes are
most likely.
Using this even if the translation makes a mistake, the
developer doesn't need to search through every line to find
them. This is ongoing, but so far this hybrid approach has
worked very well and we are on-track to shave almost one-million
dollars from the estimated migration cost.